
Data transfer over the Internet starts with an event. The event can be of human origin, for example, you start the browser (a client program) on your computer and request for some information, say an HTML file, located on a remote computer. There are two important ways in which information is requested from a browser, a hyperlink is clicked or a URL is entered in the “Address” or “Location” field.
The event can also be generated from the instructions in a program. Thus, we can automate uploading and downloading of files (data transfer) with the help of a program.
Sponsored Links
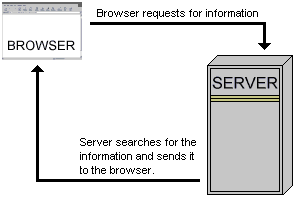
Let us suppose you have requested for an HTML document from a remote computer using a web browser. The browser searches for the remote computer and on locating it, passes the request to a program called the server running on this distant computer. The server then checks up your request and tries to locate the HTML file on its hard disk. On finding it, the server sends this file to your computer. If this HTML document has embedded image, video, and/or sound files, the information and the content of such files are also passed to the browser.
On receiving data from the server, the client which is a browser in our case, starts to display the HTML page. The client holds the sole prerogative on document display, with no involvement from the servers’ side. Once it sends the data to the remote computer, the server, so to say, washes its hands off it. On receipt of all requested data, the client-server connection is lost. Thus, the next time this client asks for some information from the server, the server will treat it as a new request without any recollection of previous requests. This means that client-server interaction is “stateless” with every new request generating a new response.
In addition to the browser, I would like to mention other clients that you might come across – email clients, the FTP client and the Telnet client.





